

茶产业作为我国特色优势产业,承担着支撑茶区经济、满足健康消费、稳定扩大就业、服务乡村振兴的重要任务。揉捻是茶叶加工的一道关键工序,主要有三个目的:一是揉捻茶叶成形,为成品茶外形打基础,二是使茶叶细胞破损、茶汁溢出,三是为后续茶叶加工做准备。揉捻机是目前能够完成茶叶揉捻工艺的主要设备,主要由揉捻盘、揉捻桶与加压装置、传动机构等结构组成,揉桶在曲柄等机构的带动和控制下,在揉捻盘上做相对偏揉捻轴中心的横向旋转。茶叶在揉桶中随着揉桶的运动不断往复翻转,并在揉盘上进行来回揉搓,逐步卷缩成条。
目前,我国茶叶花色繁多,揉捻工艺要求各有不同,揉捻速度、揉捻压力、揉捻时间设置不能一概而论,难以给出揉捻参数具体确定值。揉捻茶叶时,制茶者需要有一定的制茶经验,根据实际的鲜叶状况和环境条件对工艺进行选择,揉捻工艺受人主观能动性影响,易造成揉捻品质不一。张问采等提出利用大数据技术,对茶叶原产地的温度、气候、海拔等地理信息进行系统收集,建立茶叶加工工艺参数库,以确保茶叶揉捻加工工艺的统一性和标准性。新技术与揉捻工艺的结合能够智能选择揉捻工艺参数,对当前茶叶揉捻设备发展具有一定现实意义。
文章基于XGBoost算法设计茶叶揉捻推荐系统,通过对鲜叶等级、茶叶种类、茶叶产地以及揉捻机型号作为系统输入,能够对揉捻相关参数进行推荐。

▲ 浙江春江茶叶机械揉捻机组
01
方法原理
1、随机森林算法
随机森林算法(Random Forest)是一种集成学习方法,通过构建多个决策树来进行分类或回归。随机森林是从原始训练样本集N中重复抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质就是将多个决策树合并在一起,大大提高决策树的运算效率,每棵树都是从一个独立样本中抽取出来的,并且其分布也是一致的,所以分类误差取决于每棵树的分类能力以及树之间的相关性。CART决策树是随机森林算法弱分类器的核心部分,优点在于:当数据集的因变量是离散型数值时,此树就是分类树;当数据集的因变量是连续性数值时,此树就是回归树,预测值可以用叶节点观察的均值来表示。
随机森林算法容易实现,在训练速度方面和训练高度并行化方面也具有明显优势,还能进行模型融合,提高模型的准确性和稳定性。并且由于采用了随机采样,可以训练出方差小、泛化能力强的模型。
2、XGBoost算法
XGBoost算法(eXtreme Gradient Boosting)是一种强大集成学习方法,同时支持CART树和线性分类器为基分类器,基于前向分布算法实现加法模型的集成学习方法。集成模型的基本理念是通过构建一系列弱基础模型来构建一个强大的模型。XGBoost算法核心思想是通过持续的增加树,不停地进行特征分裂来生长一棵树、添加一个树的过程,实际上就是学习一个新函数的过程,拟合上次预测的残差。构建出k棵树,并且每棵树都能够模型化,从而模型化出每个样本的分值,从而达到对未知值的准确估计。通过观察这个样本的特征,会发现它会落在每棵树的一个对应的叶节点上,每个叶节点对应一个分数。最后,只需要将每棵树的相应分数相加,就可以得到样本的预测值。
XGBoost算法具有以下优点:
(1)简单易用,提供API方便用户使用。
(2)灵活性高,可应用于多种类型数据集和任务,包括分类、回归、排名和推荐等。
(3)准确率高,在分类和回归问题上可以达到其它算法难以匹敌的准确率。
(4)可解释强,提供丰富的特征重要性评估方法,可帮助用户理解模型预测过程。
3、支持向量机
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,主要用于分类和回归问题。它的基本原理是通过找到一个最优的超平面,将数据分为不同的类别。最优超平面是n-1维的线性子空间,其中n是数据的特征维数。例如,如果数据有两个特征,那么超平面是一维的线性子空间,也就是一个直线;如果数据有三个特征,那么超平面是个二维的线性子空间,也就是一个平面。在二维空间中,超平面就是一个直线,它将数据分为两个类别。通过SVM,可以利用一些数学技术,将复杂的高维数据转换为简单的低维数据,从而有效地解决高维数据分析的问题。
支持向量机算法具有适应性广泛、可解释性强、计算复杂度低的优点。支持向量机算法可用于线性和非线性问题,在分类和回归任务中表现出色,预测精度高,还能够清晰表示分类和回归的决策边界和数据分布情况。
02
模型搭建
1、模型搭建及训练测试
根据XGBoost的算法原理并使用Python语言,构建出XGBoost算法测试模型框架,如图1所示。一共分为四个部分,一是样本数据预处理,二是参数调优,三是模型训练,四是模型预测。
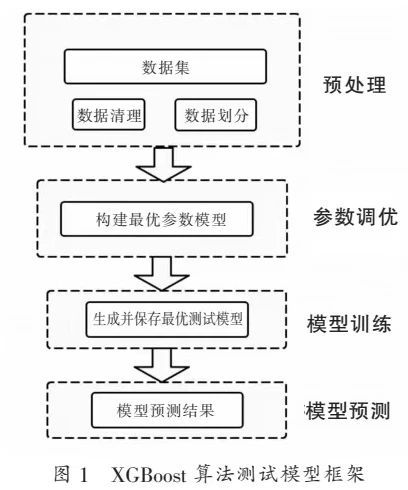
(1)数据预处理
文章数据是由广西昭平仙峰茶厂提供,获取时间为2023年3~4月。在当地5位制茶师傅的指导下,采用6CR-35型茶叶揉捻机进行数据获取。获取相关数据信息如表1所示。试验获取的数据还不能直接使用,因为初始数据中包含揉捻品质指标不符合揉捻机性能指标的揉捻参数数据,会降低模型学习效率和预测精度。在数据使用前需要对数据进行预处理,此次试验预处理主要为数据清理和数据划分。

· 数据清理
在当地制茶师傅指导下采用6CR-35型茶叶揉捻机对三级鲜叶制成红茶春茶来进行揉捻,揉捻过程中受人主观能动性影响。试验获取的100组数据中,有8组数据的破茶率、成条率、细胞破碎率不符合35型茶叶揉捻机标准,这些数据对后续揉捻参数预测没有相关性,模型分析预测数据时需要去除这些数据。
· 数据划分
将剩余92组数据按照9∶1的比例分为训练样本和测试样本。训练样本用于算法迭代学习,测试样本用于检测算法预测效果。
(2)参数调优
XGBoost算法参数包括通用参数、Booster参数和学习目标参数。通用参数能够进行宏观函数控制,Booster参数控制决策树生成和组合过程,学习目标参数能够控制训练目标。
· 通用参数:
①booster:用于选择每次迭代模型的类别。booster参数有gbtree和gblinear两种选择,gbtree是基于树结构来构建模型,而gblinear是基于线性分类器来构建模型。②silent:用于决定运行过程中是否产生输出。
· Booster参数
①n_estimators:树的数量,用于控制模型的复杂度和训练时间。②learning_rate:学习率,用于控制模型参数的更新速度,并且通过不断降低学习率来提升模型的准确性。③gamma:控制节点分裂需要的最小目标函数下降量,用于控制树的生长和防止过拟合。④subsample:样本采样比例,用于控制每个树节点上的样本数量。⑤colsample_bytree:控制每棵树中列的子采样比例。⑥colsample_bylevel:控制每一层中列的子采样比例。⑦max_depth:树的最大深度,用于控制树的复杂度,并避免过拟合。⑧max_delta_step:树模型权重改变的最大步长,控制每个树模型权重改变的最大步长,防止过拟合。⑨lambda和alpha:正则项中λ和γ的权重,减少模型过拟合。⑩scale_pos_weight:调整正样本的权重,提高模型的分类准确率。
· 学习目标参数
①objective:指训练模型时所采用的损失函数,常见的有reg:linear、reg:logistic、binary:logistic等。②eval_metric:评估模型性能指标,常见的有rmse、mae、errors等。
· GridSearch是一种参数调优方法,通过在指定的参数范围内搜索最优参数组合来优化模型性能。其步骤如下:
①确定需要调优的参数和参数取值范围。②将参数和参数取值范围组合成一个参数网格。③通过采用交叉验证的方式,对各种参数组合进行全面的性能评估。④选择最优的参数组合,并使用所有训练数据重新训练模型。⑤对数据进行测试,评估模型性能。
在实际应用中,由于参数组合数量可能很大,所以使用GridSearch时需要注意以下几点:①尽量限制参数取值范围,避免搜索空间过大。②优先选择影响模型性能最大的参数进行调优。③结合模型的特性和实际需求,选择合适的交叉验证方式。④可以使用并行计算加速参数搜索。
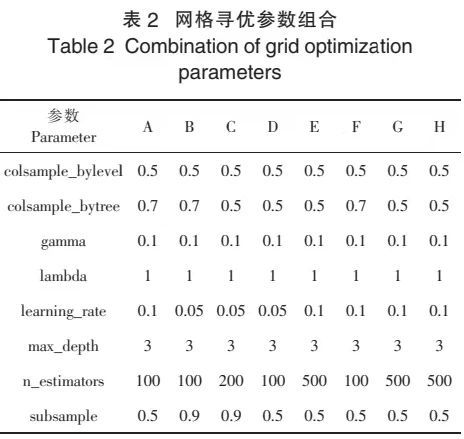
利用网格寻优调优方法分别对茶叶揉捻工艺中揉捻转速(A)、空揉时间(B)、一次轻压(C)、一次轻压时间(D)、重压(E)、重压时间(F)、二次轻压(G)、二次轻压时间(H)的参数进行网格寻优,其最优参数组合如表2所示。
(3)模型评价指标
在评价模型的预测能力时,通常采用平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squared Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)作为模型评价指标。平均绝对误差是预测值与真实值之间误差绝对值的平均值,反映了预测误差的实际情况;均方根误差是预测值与真实值之间误差平方和与样本数量比值的平方根,反映了误差分布的离散程度;平均绝对百分比误差是比较预测值与真实值之间相对误差绝对值的平均值的大小,反映了预测误差与真实值的相对大小。其表达式如式1、2、3所示,RMSE指标、MAE指标、MAPE指标得分越小,预测效果越好。

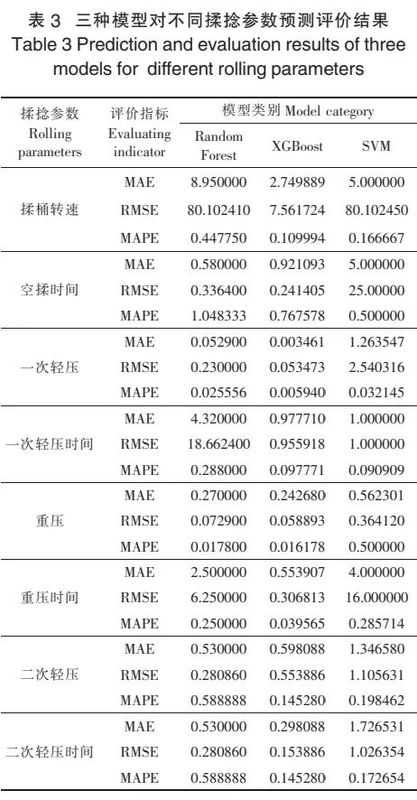
2、预测结果分析
三种算法模型对揉桶转速、空揉时间、一次轻压、一次轻压时间、重压、重压时间、二次轻压、二次轻压时间预测评价结果分别如表3所示。从RMSE、MAE、MAPE三项评价指标结果来看,XGBoost模型评价指标数值最小、算法优势显著,这表明在最优参数组合的选择下,XGBoost算法模型的预测能力较好,因此系统将XGBoost算法作为茶叶揉捻推荐系统的核心,仅使用XGBoost算法模型进行下一步分析预测。
03
推荐系统软件设计
1、系统环境
系统硬件环境和软件环境具体介绍如表4和表5所示。


2、系统主要功能实现及展示
(1)信息获取模块
茶叶推荐系统的信息获取界面可读取用户选择或输入的相关参数,完成相关数据输入功能。用户在该界面上选择茶叶种类、茶叶类型等信息,并将上述参数以文本读取方式发送至数据处理层,进行相关揉捻参数预测。
在信息获取界面中需要对茶叶等级、茶叶种类、揉捻机型号、茶叶产地信息进行输入。2016年,中国工业和信息化部颁布了JB/T 12835—2016行业标准确定茶叶等级,并以其特定的长度和比例,对茶叶级别进行了精确的划分。鲜叶长度不大于30 mm的占60%以上的为一级鲜叶、鲜叶长度不大于40 mm的占70%以上的为二级鲜叶、鲜叶长度不大于50 mm的占70%以上的为三级鲜叶、其它鲜叶为四级鲜叶。茶叶种类根据茶叶品种和制茶季节进行划分,主要划分为红茶春茶、红茶秋茶、绿茶春茶、绿茶秋茶四个类别。茶叶揉捻机型号按照揉捻桶直径大小可分为25型、35型、45型、55型等。
(2)揉捻参数推荐模块
信息获取层模块将获得的茶叶相关信息按照其所属的茶叶等级、茶叶种类、揉捻机型号以及茶叶产地信息进行分类,找到对应数据库。根据历史制茶经验数据中揉捻品质数据和揉捻工艺数据对XGBoost模型训练,此系统内将最优揉捻品质参数作为模型输入来预测茶叶揉捻工艺参数。
此揉捻参数推荐系统还具有数据保存、用户管理、操作日志、帮助文档功能,数据保存指的是可对当前获取信息以及推荐信息按照当前鲜叶等级、茶叶种类、揉捻机型号、茶叶产地的不同进行分类保存。用户管理模块仅涉及个人信息管理,用户可通过设定好的账号密码进行登录。操作日志管理记录系统运行情况,主要是系统运行过程中所产生的信息日志。帮助文档主要阐述了此推荐系统设计目的以及其使用场景。
04
推荐系统测试
1、试验目的与试验指标
揉捻推荐系统主要功能是根据不同类型鲜叶状态来推荐其揉捻参数,为了验证推荐揉捻参数的实用性,主要选取了茶叶揉捻后的碎茶率、成条率、细胞破坏率进行测定。
(1)碎茶率测定
试验碎茶率测定是通过称重完成的。在揉捻试验完后,取出茶叶进行称重,称重后通过网筛进行筛选,再将筛除的碎末碎叶进行称重。碎茶重量再除以茶叶总重得到破碎率,具体公式如式4所示。
式中:S为碎茶率;mS为碎茶重量;m为茶叶总重量。
(2)成条率测定
试验成条率测定也是通过称重完成的。在揉捻试验结束后,取出茶叶进行称重,挑出成条进行称重。成条率可通过成条叶重量除以茶叶总重,具体公式如式5所示。
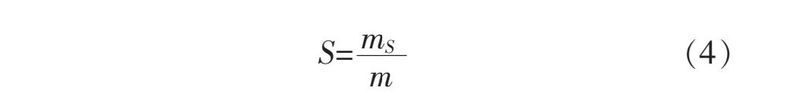
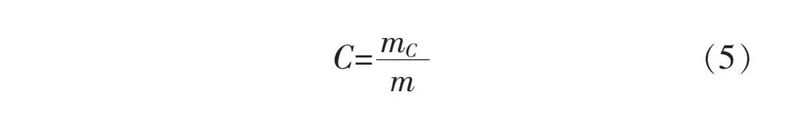
式中:C为成条率;mC为成条茶叶重量;m 为茶叶总重。
(3)细胞破坏率测定
采用计算机图像处理技术来进行茶叶细胞破坏率测定。取揉捻好的茶叶若干,放入100 ℃水浴处理15 min;在当前温度和处理时间下,破碎细胞外溢,茶多酚氧化形成茶色素并对受损细胞进行染色。将处理过的茶叶展开在白纸上进行拍照;将图片导入电脑、采用Grabcut算法删除背景;根据颜色特征计算染色面积与叶片面积比值,得到细胞破坏率。
2、推荐系统参数试验
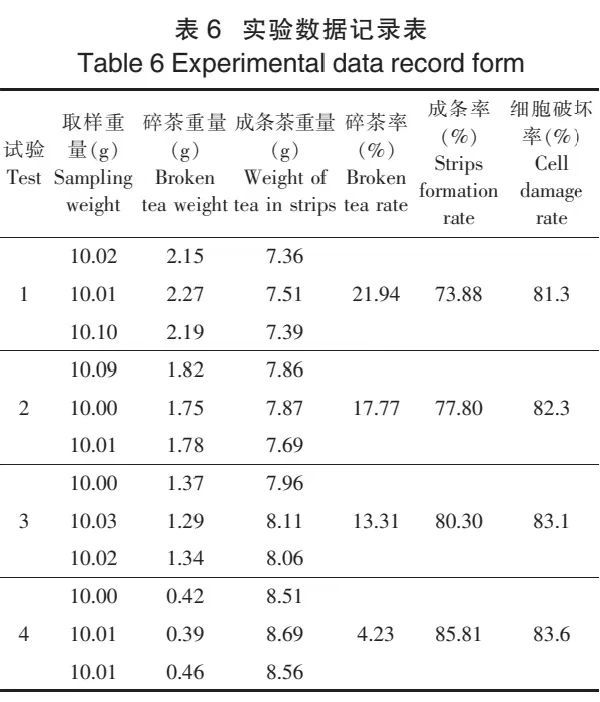
现对一批鲜叶进行揉捻参数推荐,鲜茶产地来源于广西昭平,鲜叶等级为三级,采用35型茶叶揉捻机进行揉捻,所要制成茶叶种类为红茶春茶。揉捻参数推荐系统接收到信息获取层所传送的相关信息,找到鲜叶等级为三级鲜叶、茶叶种类为红茶春茶、揉捻机型号为35型、茶叶产地为广西昭平的数据库。由于当前茶叶揉捻机采用的是固定位置揉捻,所以试验中以下降距离为控制参数。对数据库里历史揉捻参数数据进行训练,并推荐出茶叶揉捻工艺参数,揉捻转速35 r/min、空压揉捻时间为15 min、一次轻压位置为8 cm处、揉捻时间为11 min、重压压力位置为13 cm处、重压时间10 min、第二次轻压压力大小为7 cm处、揉捻时间为13 min。将揉捻工艺参数应用到35型茶叶揉捻机进行揉捻,揉捻结束后取出部分茶叶,进行筛选、称重,计算破茶率和成条率,并用计算机图像处理技术检测茶叶揉捻后细胞破碎率。
查找茶叶揉捻机作业性能指标表,可以得出6CR-35型揉捻机揉捻红茶,揉捻加工后的作业性能指标应满足成条率≥85%、碎茶率≤4.2%、茶叶细胞破坏率≥83%。茶叶揉捻机揉捻结果如表6所示,试验1是根据20次揉捻数据进行推荐,试验2是根据40次揉捻数据进行推荐,试验3是根据60次揉捻数据进行推荐。从表中试验1、试验2、试验3可以看出随着试验次数增加,揉捻叶的成条率逐渐增加、碎茶率逐渐降低、茶叶细胞破碎率逐渐增加。由于现有历史揉捻数据量较少,揉捻参数推荐系统推荐数据还不完善。试验4是根据80次揉捻数据进行推荐,可以看出揉捻后的碎茶率、成条率以及细胞破坏率已达到揉捻机作业性能指标。因此,随着后续试验数据增加,推荐系统不断进行学习优化,按照此系统推荐参数进行揉捻,茶叶揉捻品质将越来越好。
05
讨论
茶叶揉捻品质易受制茶师傅主观因素影响,通过对鲜叶等级、茶叶种类、茶叶产地以及揉捻机型号来确定揉捻工艺参数,能够保证茶叶揉捻品质稳定。文章将XGBoost算法用于茶叶揉捻参数推荐,利用真实揉捻工艺相关参数对预测模型进行验证,在参数推荐过程中展现了较强性能。根据此算法设计出茶叶揉捻参数推荐系统,并对推荐系统推荐参数进行试验。从推荐系统参数试验可以看出揉捻后的碎茶率、成条率以及细胞破坏率已达到揉捻机作业性能指标,并且随着试验数据增加,推荐系统不断学习优化,按照推荐参数进行茶叶揉捻,揉捻品质将越来越好。此揉捻推荐系统对当前茶叶揉捻设备发展具有一定现实意义。
作者简介:
陈侠
安徽宿州人,南京农业大学人工智能学院硕士研究生,研究方向为智能农业装备。
通讯作者:
柳军
副研究员,南京农业大学人工智能学院硕士生导师,研究方向为智能农机装备。
来源:中国茶叶加工
如有侵权请联系删除










